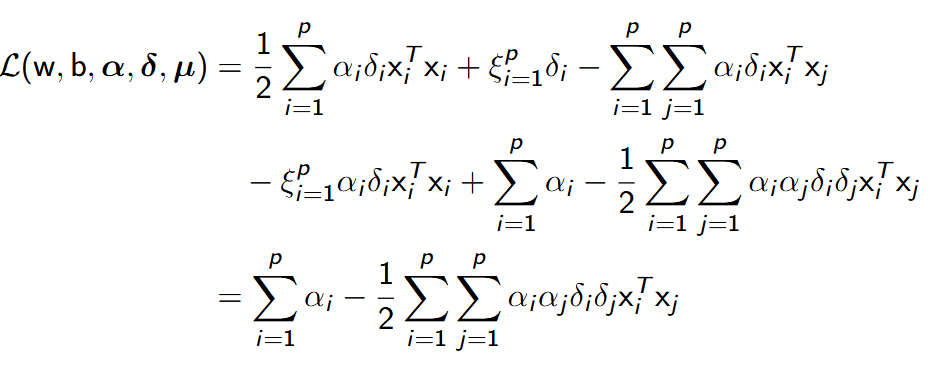Support Vector Machine SVM
Prof. V. Vapnik w 1998 r. stworzył nowe podejście do kształtowania struktury sieci neuronowej oraz definiowania problemu uczenia próbując wyeliminować znane wady sieci neuronowych typu MLP i RBF stosujące minimalizację nieliniowych funkcji błędu.
Problemy z sieciami MLP i RBF
- Minimalizowana funkcja błędu jest zwykle wielomodalna względem optymalizowanych parametrów i posiada wiele minimów lokalnych.
- Algorytm uczący nie jest w stanie skutecznie kontrolować złożoności struktury sieci neuronowej.
Nowe podejście
- Proces uczenia jest przedstawiony jako proces dobierania wag, w którym maksymalizowany jest margines separacji oddzielający skrajne (najbliższe) punkty w przestrzeni danych definiujących różne klasy.
- Bierze się pod uwagę tylko te najtrudniej separowalne punkty przestrzeni przy budowie modelu, które określają tzw. wektory nośne
Sieci SVM
- Sieci SVM tworzą specyficzną dwuwarstwową strukturę neuropodobną stosującą różne rodzaje funkcji aktywacji (liniowe, wielomianowe, radialne, sigmoidalne).
- Uczenie oparte jest na programowaniu kwadratowym, które charakteryzuje się istnieniem tylko jednego minimum globalnego.
- Dedykowane głównie do zagadnień klasyfikacji, w których jedną klasę separujemy możliwie dużym marginesem od pozostałych klas.
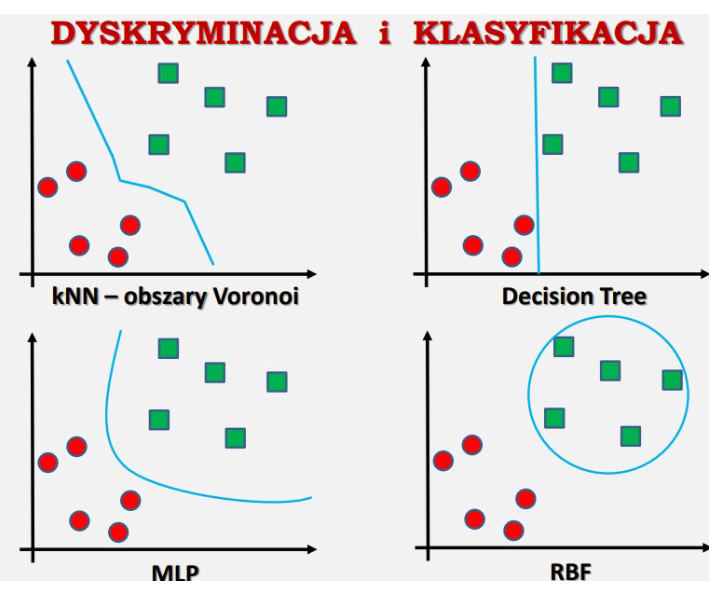
Klasyfikacja
- Klasyfikacja odnosi się do procesu przypisywania obiektów do określonych klas lub kategorii na podstawie ich cech.
- Jest to zadanie nadzorowane uczenia maszynowego, gdzie algorytm uczony jest na podstawie danych zawierających etykiety klas dla każdego obiektu.
- Celem klasyfikacji jest zbudowanie modelu, który potrafi przewidywać klasę nowych, nieznanych obserwacji na podstawie wcześniej widzianych danych uczących.
Dyskryminacja
- Dyskryminacja, w kontekście analizy danych, odnosi się do procesu identyfikowania różnic lub zależności pomiędzy różnymi grupami obserwacji.
- Może to obejmować identyfikację cech lub wzorców, które rozróżniają jedną grupę od drugiej.
- Dyskryminacja może być wykorzystywana jako część procesu klasyfikacji, gdzie celem jest znalezienie tych cech lub wzorców, które są istotne dla rozróżnienia między klasami.
Podsumowanie
- Klasyfikacja skupia się na przewidywaniu klas dla nowych obserwacji.
- Dyskryminacja skupia się na analizie różnic między grupami danych.
- Dyskryminacja może być używana jako narzędzie w procesie klasyfikacji do identyfikowania istotnych cech lub wzorców, które pomagają w dokonywaniu trafnych predykcji klas.
Metoda SVM
- Metoda Maszyny Wektorów Nośnych (SVM) ma na celu wyznaczenie najszerszej granicy dyskryminacji spośród możliwych, których zwykle istnieje nieskończona ilość.
- Jest to istotne, ponieważ większa szerokość granicy może przekładać się na lepszą zdolność generalizacji modelu i lepszą wydajność predykcyjną.
- SVM dąży do maksymalizacji marginesu separacji pomiędzy klasami, co prowadzi do wyznaczenia granicy, która jest możliwie najbardziej oddalona od punktów danych obu klas.
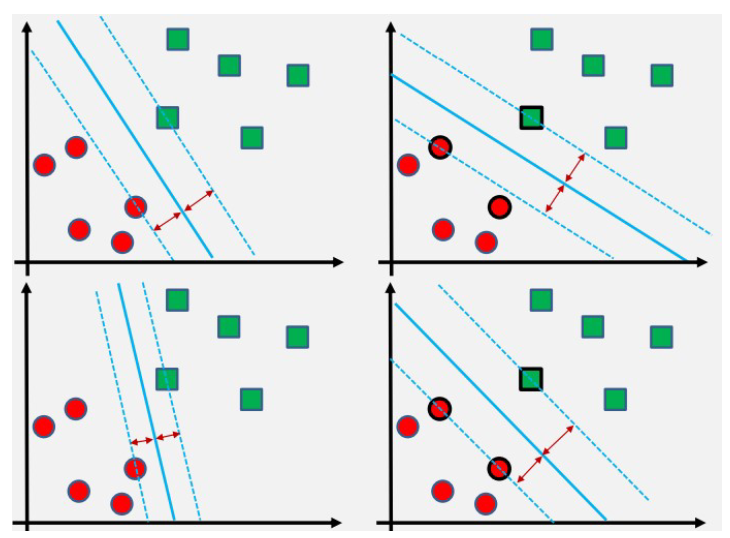
Maksymalizacja marginesu oddzielającego klasy
- Aby osiągnąć jak najlepszą dyskryminację wzorców poszczególnych klas, warto zmaksymalizować margines oddzielający te klasy.
- Margines ten to odległość pomiędzy najbliższymi punktami różnych klas a hiperpłaszczyzną separującą te klasy.
- Im większy margines, tym większa szansa na poprawne oddzielenie klas i lepszą generalizację modelu.
Ograniczenie analizy do najtrudniejszych punktów przestrzeni
- Gdy mamy do czynienia z wieloma danymi, można ograniczyć analizę tylko do tych punktów, które są najtrudniejsze do zdyskryminowania.
- Koncentrując się na tych trudnych przypadkach, model może być lepiej dopasowany do rzeczywistych warunków i mieć lepszą zdolność do rozróżniania klas
Charakterystyka modelu uwzględniającego najtrudniejsze wzorce
- Model uwzględniający najtrudniejsze wzorce powinien cechować się dobrą jakością oraz prostotą reprezentacji.
- Poprzez skupienie się na trudnych przypadkach, model może być bardziej adekwatny do rzeczywistych warunków, co może prowadzić do lepszych wyników w klasyfikacji.
Wyznaczenie optymalnej hiperpłaszczyzny dyskryminującej klasy
- Aby rozróżnić wzorce jednej klasy od pozostałych, należy wyznaczyć optymalną hiperpłaszczyznę dyskryminującą.
- Hiperpłaszczyzna ta powinna jak najlepiej oddzielać klasy, aby minimalizować błędy w klasyfikacji.
Opis algorytmu SVM
- Załóżmy, że mamy zbiór p par uczących: xi , di dla i = 1, 2, . . . , p, gdzie xi to wektor danych wejściowych, a di ∈ {−1, +1} reprezentuje dyskryminowane klasy: di = +1 oznacza klasę dyskryminowaną, zaś di = −1 oznacza pozostałe klasy.
- Przy założeniu liniowej separowalności obu klas możliwe jest określenie równania hiperpłaszczyzny separującej te wzorce: wTx + b = 0, gdzie w to wektor wag, x to wektor danych wejściowych, a b to polaryzacja.
- Możemy więc zdefiniować równania decyzyjne:
- Jeżeli wTx + b ≥ 0 to di = +1
- Jeżeli wTx + b ≤ 0 to di = −1
- Co możemy zapisać w postaci nierówności: di (wTx + b) ≥ 1, której spełnienie przez pary punktów xi , di definiuje wektory nośne (support vectors), które decydują o położeniu hiperpłaszczyzny i szerokości marginesu separacji.
- Potrzebne jest więc wyznaczenie b oraz w, żeby określić decyzję.
Przekroczenie granic separacji
Czasami występuje konieczność zmniejszenia marginesu separacji dla problemów niecałkowicie separowalnych liniowo oraz punktów xi , di leżących wewnątrz strefy marginesu separacji, co możemy zapisać za pomocą nierówności:
di (wTxi + b) ≥ 1 − δi
gdzie:
- δi ≥ 0 i zmniejsza margines separacji.
Jeśli:
- 0 ≤ δi < 1 – wtedy xi , di leży po właściwej stronie hiperpłaszczyzny, więc decyzja o przynależności do klasy będzie poprawna, δi = 1 – wtedy xi , di leży na hiperpłaszczyźnie, więc decyzja o przynależności do klasy będzie nieokreślona,
- δi > 1 – wtedy xi , di leży po niewłaściwej stronie hiperpłaszczyzny, więc decyzja o przynależności do klasy będzie błędna.
- Określając granicę decyzyjną, należy więc możliwie zminimalizować wartość δi
Szerokość marginesu separacji
- Szerokość marginesu separacji możemy wyznaczyć jako iloczyn kartezjański wektora wag w oraz różnicy odległości dwóch wektorów nośnych x+ i x− należących do przeciwnych klas:
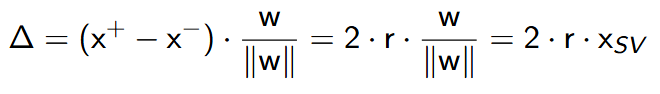
gdzie r to odległość wektorów nośnych od hiperpłaszczyzny.
- Chcąc więc zmaksymalizować margines separacji pomiędzy wektorami nośnymi różnych klas ∆ = 2 · r · w\∥w∥ , trzeba zminimalizować w, co jest równoważne minimalizacji wyrażenia 1\2 · ∥w∥\2 przy pewnych ograniczeniach liniowych wynikających ze zdefiniowanej nierówności decyzyjnej.
- W takich przypadkach stosujemy mnożniki Lagrange’a i minimalizujemy funkcję Lagrange’a.
Funkcja Lagrange’a dla maksymalizacji marginesu separacji
- Możemy więc teraz określić funkcję Lagrange’a dla problemu maksymalizacji marginesu separacji:
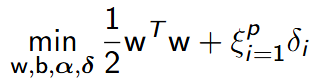
- przy zdefiniowanych ograniczeniach:
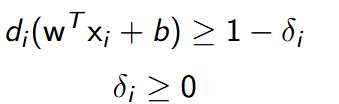
- gdzie ξ to waga, z jaką traktowane są błędy testowania w stosunku do marginesu separacji, decydującą o złożoności sieci neuronowej, dobieraną przez użytkownika w sposób eksperymentalny, np. metodą walidacji krzyżowej.
- Otrzymujemy więc następującą funkcję Lagrange’a:
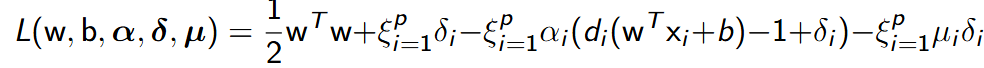
- gdzie α jest wektorem mnożników Lagrange’a o wartościach.
Rozwiązanie minimalizacji funkcji Lagrange’a polega na określeniu punktu siodłowego, czyli wyznaczenia pochodnych cząstkowych względem mnożników.
Minimalizacja funkcji Lagrange’a
- Warunki optymalnego rozwiązania wyznaczone są zależnościami:
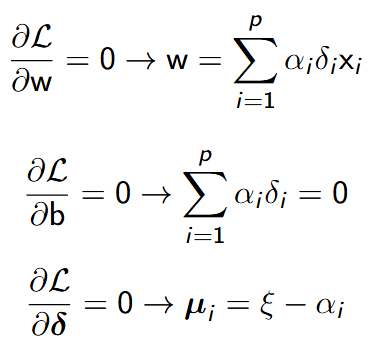
- Możemy teraz podstawić wyznaczone zależności do funkcji Lagrange’a: