Zarządzania i utrzymywania modeli ML
Co to jest MLOps?
Definicja:
MLOps (skrót od Machine Learning Operations) to zestaw praktyk, procesów i narzędzi służących do zarządzania pełnym cyklem życia modeli uczenia maszynowego – od eksploracji danych, przez trenowanie modeli, aż po ich wdrażanie, monitorowanie i utrzymanie w środowisku produkcyjnym.
Inspiracja DevOps:
MLOps czerpie z praktyk DevOps – automatyzacji, ciągłej integracji i dostarczania (CI/CD), kontroli wersji, ale rozszerza je o specyfikę ML, czyli:
- zmienne dane wejściowe,
- ewoluujące modele,
- złożone eksperymenty,
- metryki jakości modelu.
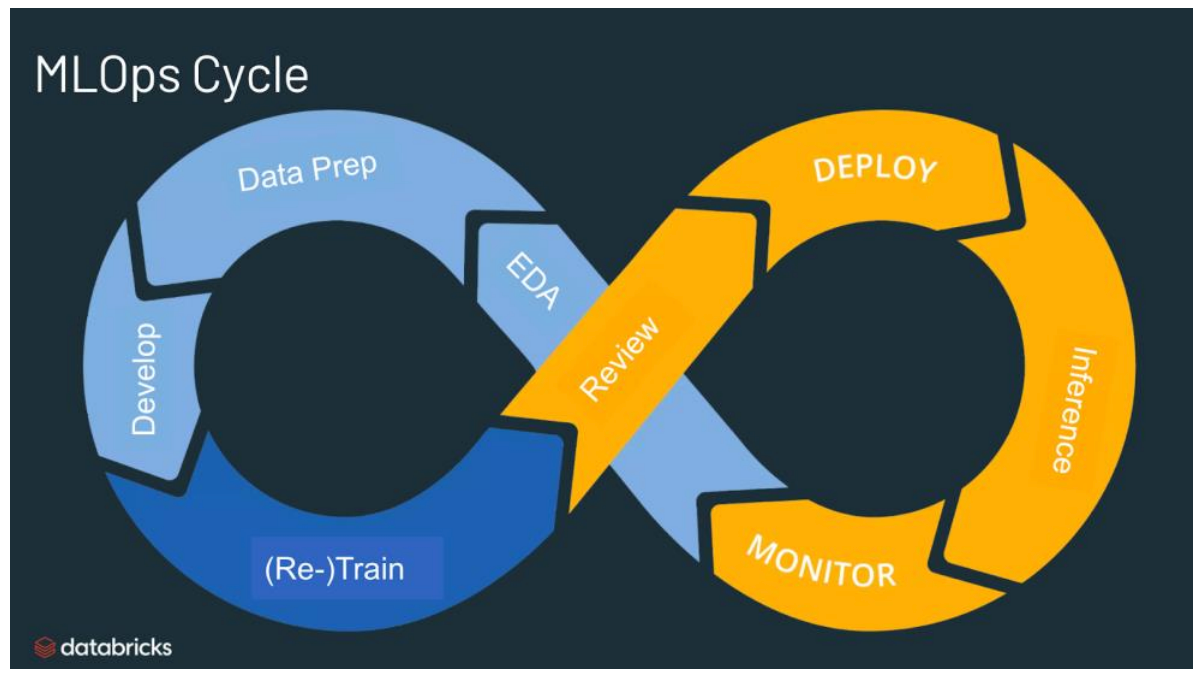
Dlaczego MLOps jest potrzebne?
Tradycyjne podejście do ML:
- Data scientist tworzy model na lokalnym laptopie.
- Wyniki są obiecujące.
- Wdrożenie zajmuje tygodnie.
- Model działa inaczej w produkcji niż w środowisku testowym.
- Brakuje wersjonowania danych, modeli, kodu.
Problemy:
- Trudność w replikacji eksperymentów.
- Ręczne procesy = podatność na błędy.
- Brak ciągłego monitoringu i retrenowania.
- Brak standardów wdrażania modeli.
Rozwiązanie: MLOps
- Automatyzacja i standaryzacja procesów ML.
- Szybsze i bardziej niezawodne wdrożenia.
- Większa przejrzystość i kontrola jakości.
- Łatwiejsza współpraca zespołów.
Etapy cyklu życia modelu ML
ETAP 1
Zbieranie i eksploracja danych
- Pozyskiwanie danych z różnych źródeł: bazy danych, API, pliki, strumienie danych.
- Walidacja jakości danych (czyszczenie, brakujące wartości, outliery).
- Eksploracyjna analiza danych (EDA).
Wyzwania:
- Dane są dynamiczne i mogą się zmieniać w czasie.
- Dane muszą być wersjonowane, aby zapewnić powtarzalność treningu.
MLOps: stosowanie narzędzi do data versioning (np. DVC), automatyczne pipeline’y przetwarzania danych.
ETAP 2
Przygotowanie danych (feature engineering)
- Tworzenie cech wejściowych na podstawie surowych danych.
- Normalizacja, kodowanie, agregacja.
- Tworzenie zbiorów treningowych, walidacyjnych, testowych.
MLOps: wykorzystanie feature store do przechowywania, wersjonowania i ponownego wykorzystania cech.
ETAP 3
Budowanie modelu (model development)
- Wybór algorytmu (np. Random Forest, XGBoost, CNN, Transformer).
- Trenowanie modeli i strojenie hiperparametrów.
- Eksperymentowanie z różnymi konfiguracjami.
MLOps: śledzenie eksperymentów (np. MLflow), automatyzacja treningu, repozytorium modeli.
ETAP 4
Walidacja i testowanie modelu
- Ocena modelu na danych walidacyjnych/testowych.
- Analiza metryk: accuracy, precision, recall, F1, AUC, RMSE itd.
- Testy jakościowe: fairness, interpretowalność.
MLOps: automatyczne testy metryk i jakości modelu (CI), walidacja przed wdrożeniem.
ETAP 5
Wdrożenie (deployment)
- Udostępnienie modelu jako REST API, batch processing lub streaming.
- Modele mogą być wdrażane jako kontenery (Docker), w chmurze lub lokalnie.
MLOps: CI/CD dla modeli – automatyzacja wdrażania (GitOps, ArgoCD, Kubeflow).
ETAP 6
Monitorowanie modelu
- Obserwacja działania modelu w środowisku produkcyjnym:
- Data drift: dane wejściowe zmieniają się w czasie.
- Concept drift: zależność między wejściem a wyjściem ulega zmianie.
- Spadek jakości modelu.
MLOps: monitorowanie metryk (np. Prometheus + Grafana, WhyLabs), alerty, retrenowanie.
ETAP 7
Aktualizacja i ponowne trenowanie (retraining)
- Gdy model przestaje działać optymalnie, należy go zaktualizować.
- Automatyczne lub ręczne uruchomienie pipeline’u trenowania z nowymi danymi.
- Wersjonowanie modeli (np. v1, v2).
MLOps: Continuous Training (CT), harmonogramy retreningu, testy A/B nowych wersji.
ETAP 7
Zarządzanie cyklem życia modeli
- Przechowywanie historii modeli, metryk, artefaktów.
- Rejestrowanie, archiwizacja, wycofywanie nieaktualnych modeli.
- Audytowalność – kluczowa dla regulowanych branż (np. finanse, medycyna).
MLOps: Model Registry (MLflow, SageMaker Model Registry), kontrola wersji i uprawnień.
Kluczowe komponenty MLOps
MLOps składa się z zestawu praktyk i narzędzi, które wspólnie tworzą kompletny, zautomatyzowany i skalowalny ekosystem dla modeli ML. Te komponenty pokrywają wszystkie etapy:
- od danych,
- przez eksperymenty,
- trening, aż po wdrożenie,
- monitoring.
Zarządzanie danymi (Data Management)
Kluczowe aspekty:
- Wersjonowanie danych (data versioning) – umożliwia odtworzenie eksperymentów na tych samych danych.
- Rejestrowanie źródeł danych – zapewnia transparentność i identyfikowalność.
- Data drift detection – monitorowanie zmian w danych wejściowych w czasie.
Narzędzia:
- DVC (Data Version Control) – wersjonowanie danych jak Git.
- Delta Lake / Apache Hudi – zarządzanie danymi w hurtowniach danych.
- Great Expectations / Evidently – walidacja danych, testy jakości.
Zarządzanie kodem i eksperymentami
Kluczowe aspekty:
- Reprodukowalność – możliwość odtworzenia wyników dowolnego eksperymentu.
- Eksperyment tracking – rejestrowanie hiperparametrów, metryk, czasu treningu, modelu.
- Zarządzanie konfiguracją – oddzielenie parametrów od kodu.
Narzędzia:
- MLflow Tracking
- Weights & Biases (WandB)
- Sacred + Omniboard
- Hydra / ConfigArgParse – zarządzanie konfiguracją.
Zarządzanie modelami (Model Management)
Kluczowe aspekty:
- Model Registry – centralne repozytorium modeli z wersjonowaniem.
- Kontrola cyklu życia modelu – od treningu do wycofania.
- Zatwierdzanie modeli do produkcji – governance + kontrola jakości.
Narzędzia:
- MLflow Model Registry
- Sagemaker Model Registry
- Kubeflow Model Management
Pipeline CI/CD/CT (Continuous Integration, Deployment, Training)
Kluczowe aspekty:
- Automatyzacja trenowania i wdrażania modeli
- Integracja z repozytorium kodu (Git)
- Testy jednostkowe, testy danych, walidacja modeli
- Ciągłe trenowanie (CT) – retrenowanie modeli, gdy zmienią się dane lub warunki.
Narzędzia:
- GitHub Actions, GitLab CI/CD
- Kubeflow Pipelines
- Apache Airflow / Prefect
- Metaflow– zarządzanie workflowami ML
Monitoring po wdrożeniu (Post-deployment Monitoring)
Kluczowe aspekty:
- Performance monitoring – jak model radzi sobie w środowisku produkcyjnym.
- Data drift / concept drift detection
- Alerty i automatyczna retrenizacja
- Logowanie predykcji, metryk, błędów
Narzędzia:
- Evidently AI
- Prometheus + Grafana
- Seldon Core (monitoring + serving)
- Fiddler AI / Arize AI – wyspecjalizowane narzędzia monitorujące
Architektura systemu MLOps
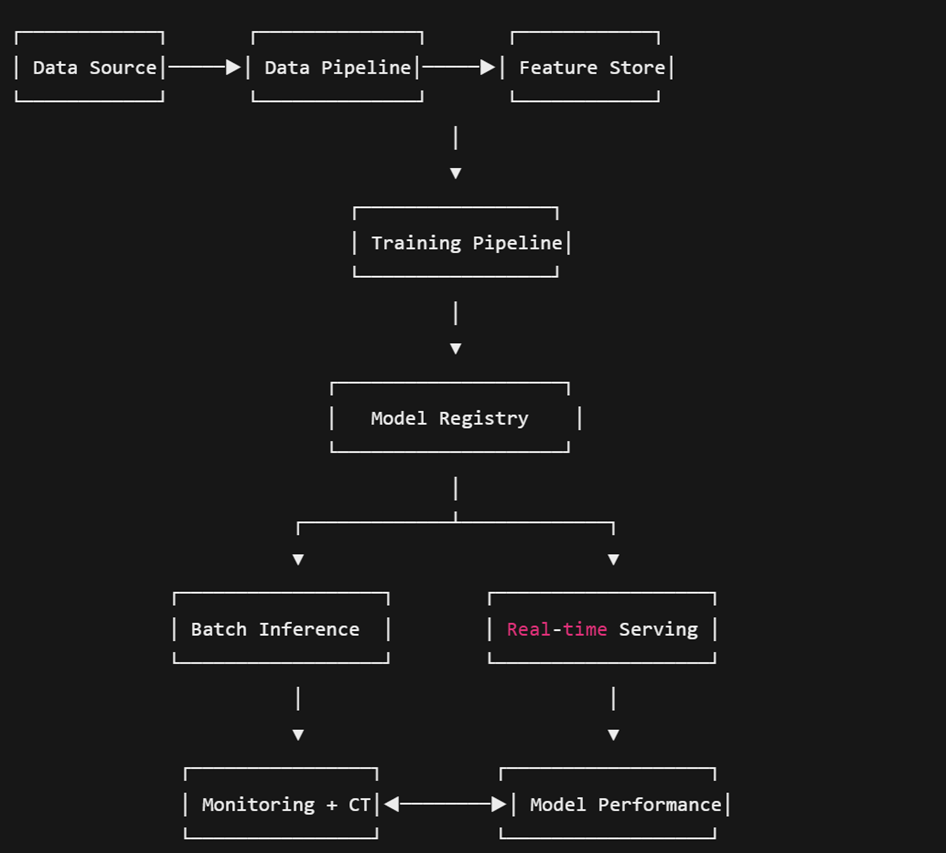
- Źródła danych (Data Sources)
- Dane mogą pochodzić z baz danych, plików CSV, strumieni (Kafka), API lub Data Lakes.
- Wyzwanie: różne formaty, jakość danych, konieczność standaryzacji.
- Feature Store
- Specjalna baza danych na potrzeby cech (features) wykorzystywanych w modelach.
- Umożliwia ponowne wykorzystanie tych samych transformacji cech w czasie treningu i inferencji.
- Przykłady: Feast, Tecton.
- Data/Feature Engineering Pipeline
- ETL/ELT procesy: ekstrakcja, transformacja, ładowanie.
- Zazwyczaj implementowane jako DAG (np. Apache Airflow, Prefect).
- Integracja z systemami do wersjonowania danych (np. DVC, Delta Lake)
- Pipeline treningowy (Training Pipeline)
- Automatyzuje trening modeli: pobiera dane, uruchamia kod ML, zapisuje wyniki.
- Kluczowe elementy:
- Śledzenie eksperymentów (np. MLflow)
- Automatyczne testy jakości danych
- Hyperparameter tuning (np. Optuna, Ray Tune)
- Rejestrowanie modeli w Model Registry
- Model Registry
- Centralne repozytorium modeli z metadanymi (wersja, autor, metryki, status).
- Umożliwia zarządzanie cyklem życia modeli: staging → production → archived.
- Przykłady: MLflow Model Registry, Sagemaker Model Registry
- Deployment (Model Serving)
- Wdrożenie modelu jako REST API, mikroserwis lub batch prediction.
- Sposoby deploymentu:
- Online (real-time): FastAPI, TensorFlow Serving, TorchServe
- Offline (batch): Airflow, Spark
- Infrastruktura: Docker, Kubernetes, serverless (AWS Lambda, Azure Functions)
- Monitoring i logging
- Monitorowanie działania modelu po wdrożeniu:
- •akość predykcji (accuracy drift, data drift)
- Czas odpowiedzi
- Wydajność systemu
- Narzędzia: Prometheus + Grafana, EvidentlyAI, Seldon Core
- Continuous Integration / Continuous Deployment / Continuous Training (CI/CD/CT)
- Automatyzacja:
- CI: testowanie kodu, budowanie obrazów
- CD: automatyczne wdrażanie modeli
- CT: automatyczne ponowne trenowanie modelu, gdy pojawią się nowe dane
- Narzędzia: GitHub Actions, GitLab CI, Jenkins, Tekton
MLflow – zarządzanie eksperymentami i modelami
Co robi?
- Rejestrowanie parametrów, metryk i artefaktów modeli.
- Tworzenie i zarządzanie model registry.
- Umożliwia deployment modeli w formatach gotowych do produkcji.
Zastosowanie: Śledzenie wyników eksperymentów; porównywanie modeli.
Alternatywy: Weights & Biases, Neptune.ai, Comet.ml
DVC (Data Version Control) – wersjonowanie danych i pipeline’ów
Co robi?
- •Przechowuje i wersjonuje dane tak jak Git kod.
- •Integruje się z Git – każda zmiana danych ma swój commit.
- •Obsługuje pipeline’y do automatycznego przetwarzania danych.
Zastosowanie: Reprodukowalność eksperymentów, kontrola wersji datasetów.
Alternatywy: Pachyderm, LakeFS, Delta Lake
Kubeflow / TFX / Metaflow – budowanie i zarządzanie pipeline’ami
- Kubeflow:
- Przeznaczony dla Kubernetes – kompleksowe środowisko do budowy i uruchamiania pipeline’ów ML.
- TFX (TensorFlow Extended):
- Pipeline’y ML od Google – głównie dla TensorFlow, ale coraz bardziej otwarty.
- Metaflow:
- Prosty interfejs do definiowania kroków pipeline’u
- Obsługuje wiele środowisk (lokalnie, chmura, Docker, AWS Batch).
Zastosowanie: Automatyzacja procesów przetwarzania danych, trenowania, testowania i deploymentu modeli.