Wprowadzenie do przetwarzania języka naturalnego
Czym jest NLP?
Natural Language Processing (NLP) to interdyscyplinarna dziedzina badań i inżynierii łącząca:
- Informatykę (algorytmy, uczenie maszynowe)
- Językoznawstwo komputerowe
- Sztuczną inteligencję
Celem NLP jest umożliwienie komputerom:
- Rozumienia
- Analizy
- Generowania
- oraz interakcji w języku naturalnym człowieka.
Przykładowe zastosowania NLP
Realne zastosowania technologii NLP:
- Asystenci głosowi (Siri, Alexa, Google Assistant)
- Tłumaczenia maszynowe (Google Translate, DeepL)
- Analiza sentymentu (np. monitoring opinii w mediach społecznościowych)
- Systemy rekomendacyjne i wyszukiwanie (Amazon, YouTube, Google)
- Rozpoznawanie i klasyfikacja dokumentów (OCR + NLP)
- Chatboty i interfejsy konwersacyjne (obsługa klienta, automatyzacja wsparcia)
Dlaczego NLP jest istotne dla informatyków?
NLP łączy klasyczne struktury danych z przetwarzaniem dużych zbiorów nieustrukturyzowanych danych tekstowych.
Umożliwia wykorzystanie wiedzy z zakresu:
- Algorytmiki (np. wyszukiwanie, parsowanie)
- Uczenia maszynowego (ML, DL)
- Przetwarzania sygnałów (dla mowy)
Coraz większa rola NLP w rozwiązaniach opartych na danych (Data Science, AI)
Reprezentacja tekstu w przetwarzaniu języka naturalnego
- Przetwarzanie tekstu w NLP wymaga przekształcenia danych językowych do postaci zrozumiałej dla algorytmów komputerowych.
- Naturalny język musi zostać zamieniony na reprezentację numeryczną, zachowującą możliwie dużo informacji semantycznych i syntaktycznych.
Podstawowe etapy przetwarzania tekstu
- Tokenizacja – podział tekstu na jednostki (tokeny), np. słowa, frazy, znaki.
- Normalizacja – ujednolicenie tekstu, np. konwersja do małych liter, usunięcie znaków interpunkcyjnych.
- Usuwanie stop-wordów – eliminacja najczęściej występujących, mało informatywnych słów (np. „i”, „to”, „jest”).
- Stemming / Lematyzacja – sprowadzanie słów do ich form podstawowych (np. „chodzący” → „chodzić”).
Reprezentacje wektorowe tekstu
Komputery nie operują na słowach, lecz na liczbach. Potrzebujemy odwzorowania słów (lub dokumentów) w przestrzeni numerycznej.
Najczęstsze techniki:
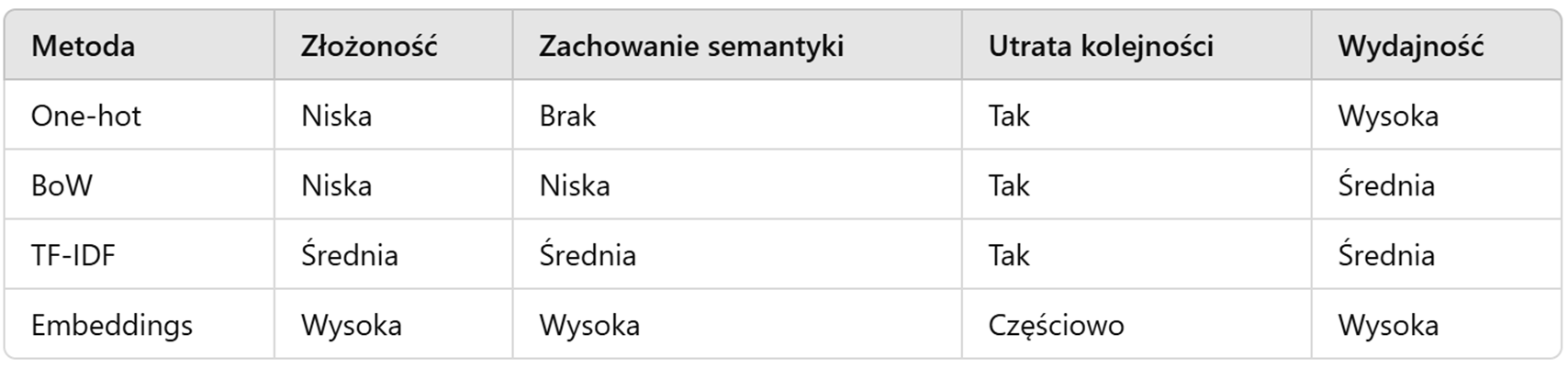
- One-hot encoding
- Bag-of-Words (BoW)
- TF-IDF (Term Frequency – Inverse Document Frequency)
- Word Embeddings (Word2Vec, GloVe, FastText)
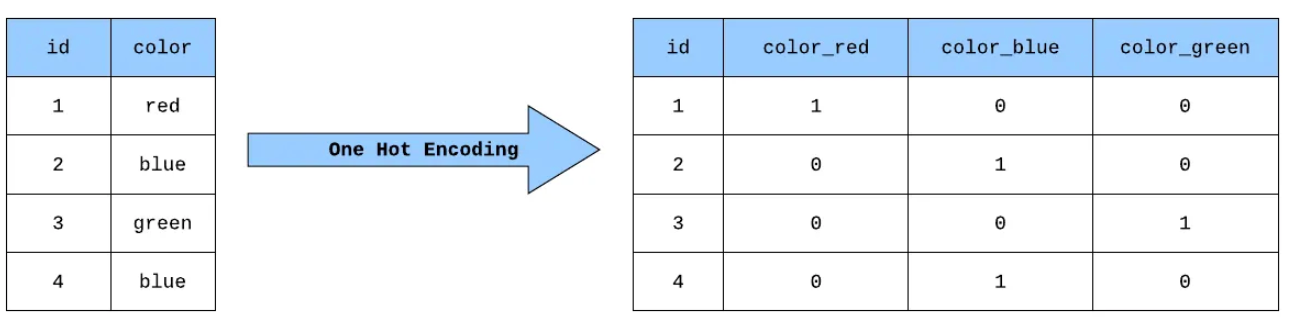
One-hot encoding
Każde słowo reprezentowane jako wektor, w którym tylko jedna wartość wynosi 1 (pozostałe 0).
Zalety:
- Prosta implementacja
Wady:
- Wysoka wymiarowość
Brak informacji semantycznych (słowa "król" i "królowa" są tak samo odległe jak "król" i "rower")
Bag-of-Words (BoW)
Reprezentacja tekstu jako wektora liczności wystąpień słów z ustalonego słownika.
Zalety:
- Łatwa implementacja
- Skuteczna w klasyfikacji tekstów
Wady:
- Ignoruje kolejność słów i składnię
- Wrażliwa na rzadkie i często występujące słowa
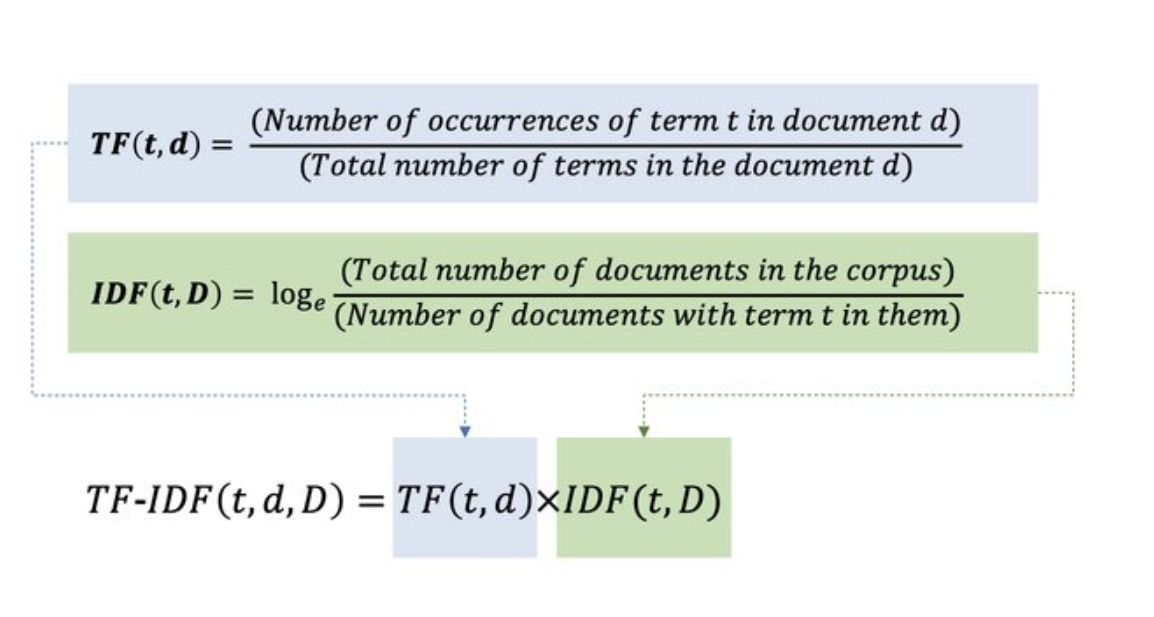
TF-IDF (Term Frequency – Inverse Document Frequency)
Wzmacnia rzadkie, ale informatywne słowa, redukuje wpływ słów występujących często w korpusie.
- TF – częstość występowania słowa w dokumencie
- IDF – odwrotność częstości dokumentowej danego słowa
Zalety:
- Lepsze od BoW w zadaniach klasyfikacyjnych
- Ułatwia rozróżnianie między dokumentami
Wady:
- Nadal ignoruje kontekst i kolejność słów
Word Embeddings
Słowa jako gęste wektory w przestrzeni ciągłej, uczone na podstawie kontekstu występowania.
Przykłady modeli:
- Word2Vec (CBOW, Skip-gram)
- GloVe
- FastText
Zalety:
- Zachowują podobieństwo semantyczne
- Efektywne i kompaktowe
- Umożliwiają operacje semantyczne (np. "król" – "mężczyzna" + "kobieta" ≈ "królowa")
Porównanie reprezentacji
Tokenizacja i segmentacja tekstu
Tokenizacja:
- Proces dzielenia tekstu na mniejsze jednostki: tokeny (słowa, znaki interpunkcyjne, liczby, itp.).
- Podstawa dla większości zadań NLP.
Segmentacja zdań:
- Rozdzielanie tekstu na zdania przy użyciu reguł językowych lub modeli statystycznych.
Przykład: Tekst: „Nie wiem, co powiedzieć. To dziwne!”
Zdania:
- Nie wiem, co powiedzieć.
- To dziwne!

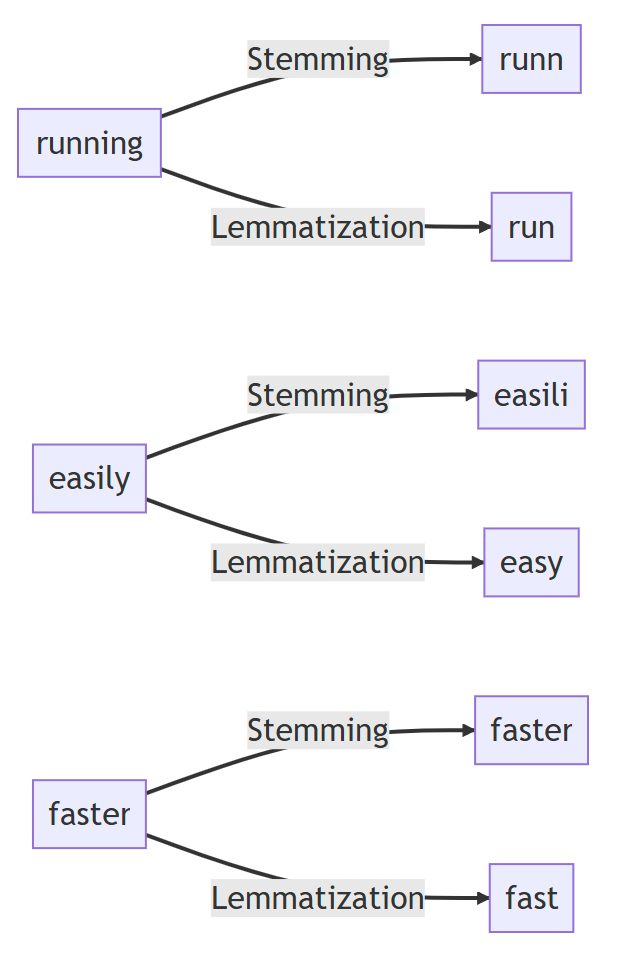
Lematyzacja i stemming
Lematyzacja:
- Redukcja słowa do jego formy podstawowej (lematu) z uwzględnieniem kontekstu gramatycznego.
- Przykład: „kupiłem”, „kupuję”, „kupisz” → „kupić”
Stemming:
- Heurystyczne skracanie słów do rdzenia (często bez uwzględnienia gramatyki).
- Przykład: „relational”, „relations”, „relation” → „relat”
Lematyzacja jest dokładniejsza, lecz bardziej kosztowna obliczeniowo.
Rozpoznawanie części mowy (POS Tagging)
Definicja:
Proces przypisywania każdemu tokenowi jego kategorii gramatycznej (rzeczownik, czasownik, przymiotnik itd.).
Znaczenie:
- Kluczowe dla dalszej analizy składniowej, lematyzacji, rozpoznawania relacji semantycznych.
Przykład: „Zamek był piękny.”
→ „Zamek” – rzeczownik (NN)
Rozpoznawanie nazw własnych (NER)
Named Entity Recognition:
- Automatyczne wykrywanie i klasyfikowanie nazw własnych w tekście:
- Osoby, organizacje, lokalizacje, daty, wartości pieniężne itd.
Zastosowania:
Ekstrakcja informacji, wyszukiwanie semantyczne, systemy rekomendacyjne.
Przykład:
„OpenAI została założona w San Francisco w 2015 roku.”
→ [ORG: OpenAI], [LOC: San Francisco], [DATE: 2015]
Analiza składniowa (Parsing)
Parsing składniowy:
- Odtwarzanie struktury gramatycznej zdania – drzewa zależności lub struktury składniowej.
Typy analizatorów:
- Constituency parsing – klasyczne podejście bazujące na strukturze frazowej.
- Dependency parsing – analiza relacji między słowami w zdaniu.
Zastosowania:
- Generowanie języka naturalnego, tłumaczenie maszynowe, QA systems.
Analiza sentymentu
Definicja:
Automatyczne wykrywanie ładunku emocjonalnego wypowiedzi (np. pozytywny, negatywny, neutralny).
Metody:
- Podejścia słownikowe
- Modele ML / deep learning (np. RNN, BERT)
Przykład:
„Film był genialny!” → Sentyment: pozytywny
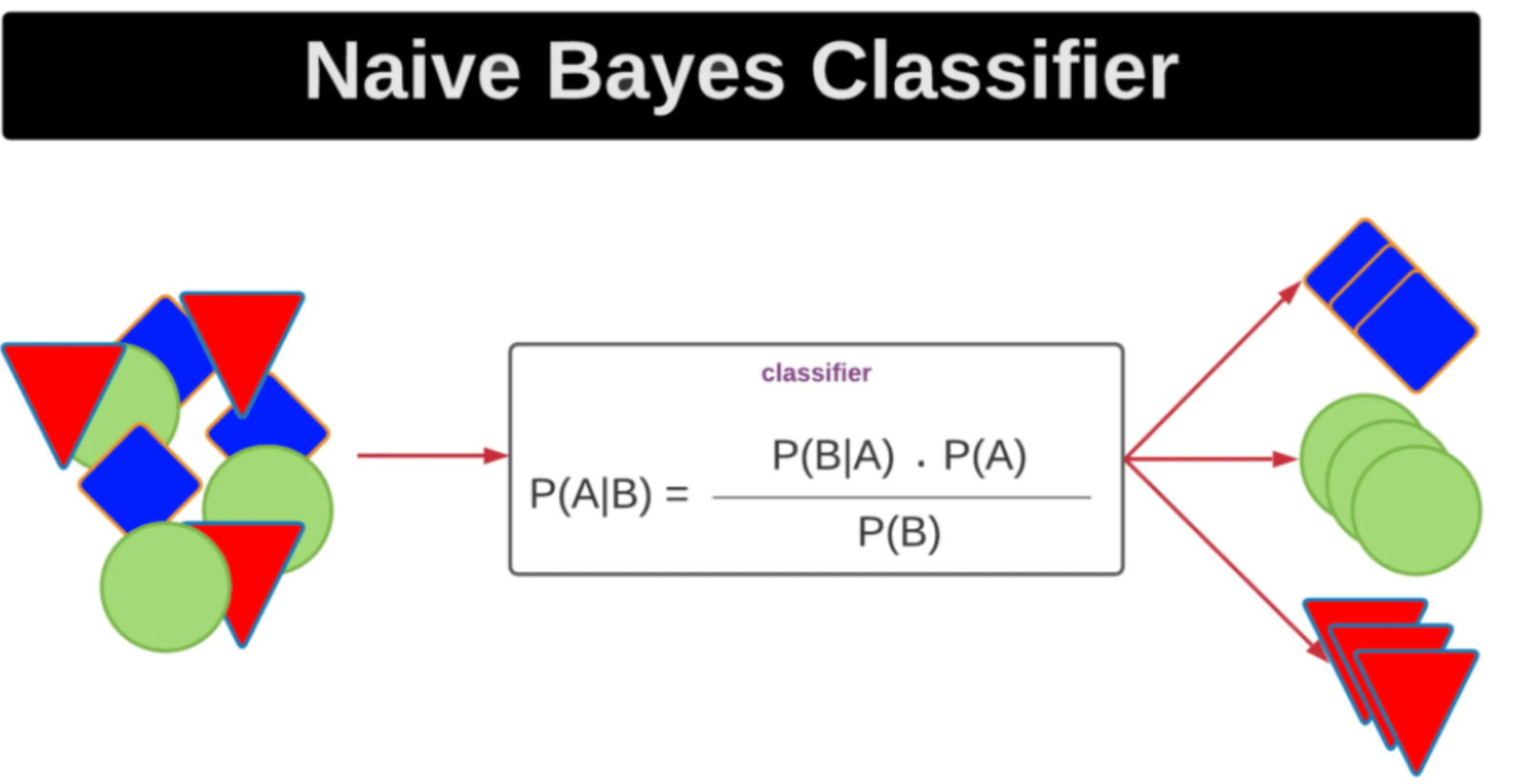
Klasyfikacja tekstu
Opis:
Przypisywanie dokumentom lub fragmentom tekstu jednej lub wielu kategorii.
Przykładowe zastosowania:
- Filtrowanie spamu
- Kategoryzacja wiadomości
- Wykrywanie mowy nienawiści
Techniki:
- Naive Bayes, SVM, drzewa decyzyjne
- Sieci neuronowe, transformery
Powiązania między zadaniami NLP
Wiele zadań tworzy pipeline NLP – np. tokenizacja → lematyzacja → POS tagging → NER → klasyfikacja.
Dobór technik zależy od:
- Języka i dziedziny tekstu
- Celu analizy
- Ilości dostępnych danych i zasobów
Modele i algorytmy w NLP – wprowadzenie
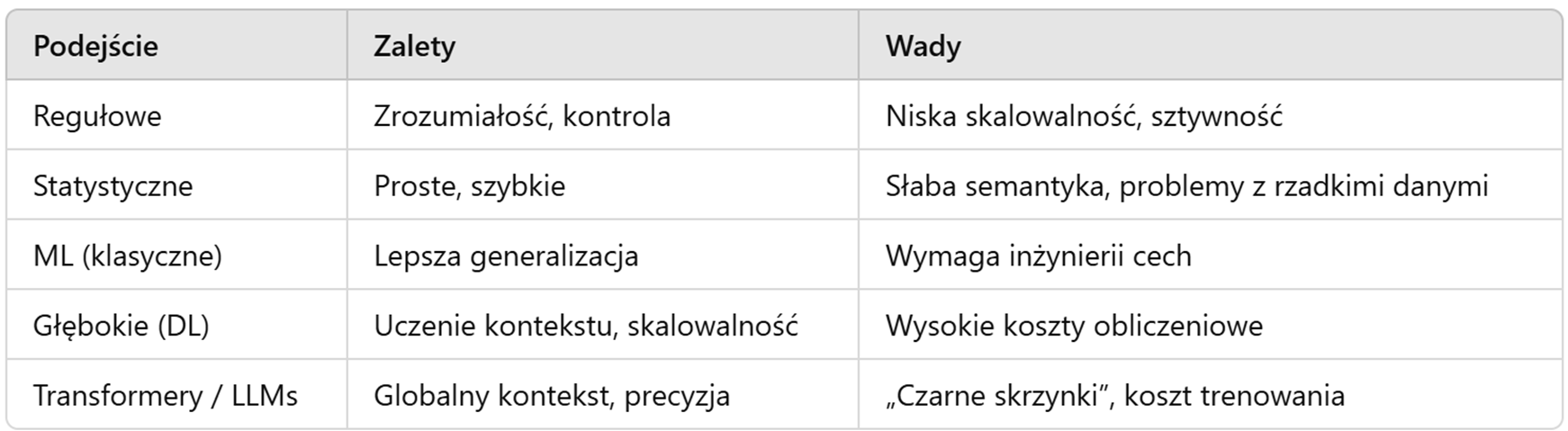
Podejście regułowe
Opis:
- Bazuje na ręcznie tworzonych regułach lingwistycznych (np. gramatycznych, morfologicznych)
- Przykłady: Reguły typu „jeśli–to”, słowniki, wzorce POS
- Dobrze sprawdza się w systemach eksperckich lub dla ograniczonych domen
Zalety:
- Łatwo interpretowalne
- Deterministyczne działanie
Wady:
- Niska skalowalność
- Duża pracochłonność tworzenia reguł
- Słaba odporność na błędy językowe i wariantywność języka
Modele statystyczne
Podejście probabilistyczne:
- Uczenie na podstawie dużych zbiorów tekstu i analiz statystycznych
- Przykłady:
- Naive Bayes – klasyfikacja tekstu
- Hidden Markov Models – rozpoznawanie części mowy
- n-gramy – modelowanie sekwencji słów
Ograniczenia:
- Krótki kontekst (np. n-gramy często ograniczone do n=2,3)
- Zanik informacji o semantyce
- Problemy ze sparsowaniem danych (wiele możliwych sekwencji rzadko występuje)
Uczenie maszynowe i głębokie
Uczenie maszynowe (ML) w NLP:
- Automatyczne uczenie reguł z danych
- Wykorzystanie cech (np. TF-IDF, embeddings)
- Algorytmy klasyczne: SVM, Random Forest, Logistic Regression
Uczenie głębokie (DL):
- Modele neuronowe przetwarzające tekst w sposób nieliniowy
- Architektury:
- RNN (Recurrent Neural Networks)
- LSTM / GRU – rozwiązanie problemu „zanikającego gradientu”
Modele językowe (Language Models)
Czym jest model językowy?
Model statystyczny lub neuronowy przewidujący kolejne słowa w sekwencji
Typy:
- n-gramowe – probabilistyczne, krótkie okno kontekstu
- embeddingowe – np. Word2Vec, FastText
- transformerowe – BERT, GPT, T5
Zastosowania:
- Autouzupełnianie
- Tłumaczenia maszynowe
- Tworzenie streszczeń, generowanie tekstu
Transformery – rewolucja w NLP
Architektura Transformer (Vaswani et al., 2017):
- Mechanizm self-attention pozwala modelowi analizować zależności w całym tekście jednocześnie
- Równoległość przetwarzania → szybsze uczenie
Najważniejsze modele:
- BERT (bidirectional, kontekstualny embedding)
- GPT (generatywny, autoregresywny)
- T5, RoBERTa, XLNet – warianty architektury
Porównanie podejść NLP