SSN - Podstawy - Rodzaje neuronów
Perceptron
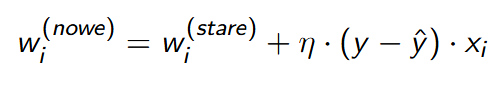
gdzie
• Aktualizacja wag
• wi(nowe) – nowa waga dla i-tego wejścia
• wi(stare) – poprzednia waga dla i-tego wejścia
• η – współczynnik uczenia
• y– rzeczywista etykieta klasy dla danego przykładu
• y^ – predykcja modelu dla danego przykładu
• xi – i-ty element wektora danych wejściowych
Funkcja skokowa
Funkcja skokowa (znana również jako funkcja Heaviside’a) to prosta funkcja aktywacji używana w wielu modelach neuronowych. Jest to funkcja, która zwraca 1, gdy argument jest większy lub równy zeru, a w przeciwnym przypadku zwraca 0.
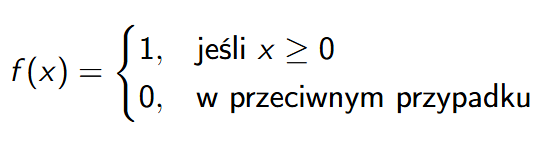
Przykład działania - Reguła uczenia
- Dane Wejściowe: (x1, x2)
- Wagi: (w1, w2)
- Bias: b
- Funkcja Aktywacji: funkcja skokowa
Iteracja 1:
- Obliczenie ważonej sumy
- Aktywacja
- Predykcja
- Aktualizacja wag
- Aktualizacja bias
Iteracja 2 (dla kolejnego przykładu):
- Analogicznie do iteracji 1
Funkcja skokowa - Wprowadzenie
Funkcja skokowa (Heaviside’a) jest jedną z podstawowych funkcji aktywacji w modelach neuronowych.
Definicja:
Funkcja skokowa (Heaviside’a) jest zdefiniowana jako:
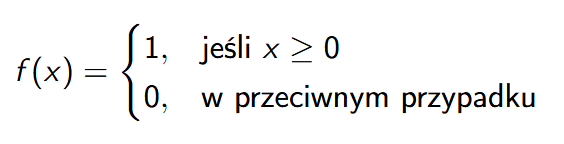
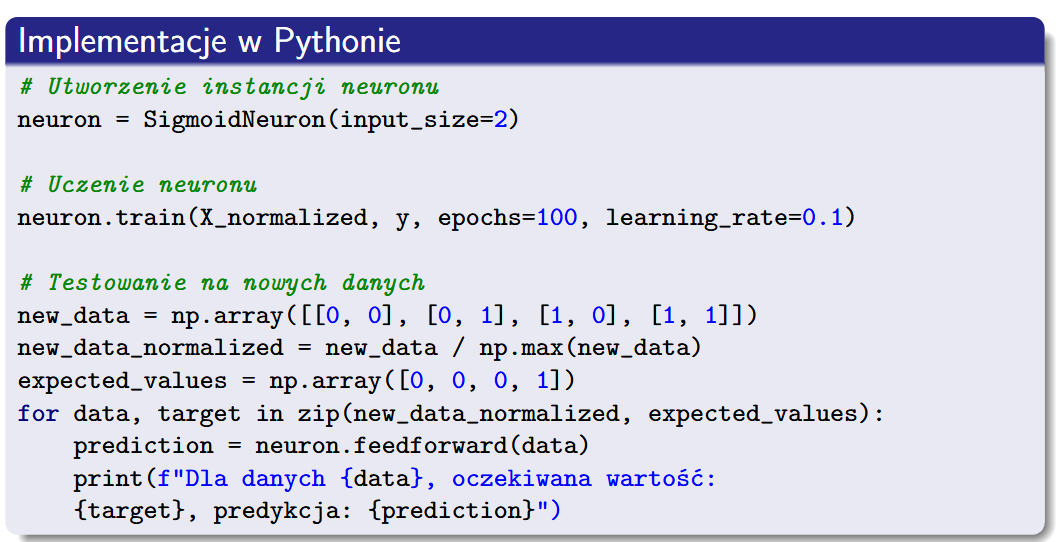
Implementacje w Pythonie

Reguła Uczenia Perceptronu w Pythonie


Funkcja Sigmoidalna
Wzór:
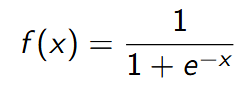
Zalety:
- Zakres wartości między 0 a 1, co jest przydatne w problemach
- klasyfikacji.
- Gładka i różniczkowalna, ułatwia propagację wsteczną.
- Reprezentuje prawdopodobieństwo, co jest użyteczne w problemach
- binarnej klasyfikacji.
Wady:
- Problem z zanikającymi gradientami w głębokich sieciach
- neuronowych.

Funkcja ReLU (Rectified Linear Unit)
Wzór:
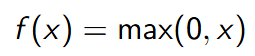
Zalety:
- Prosta w implementacji i obliczeniowo efektywna.
- Unikanie problemu zanikających gradientów.
- Szybkość zbieżności w uczeniu głębokich sieci neuronowych.
Wady:
- Niezerowa dla ujemnych argumentów, co może prowadzić do zjawiska
- zanikania neuronów.
- Brak różniczkowalności dla x=0, co może stanowić problem w
- niektórych metodach optymalizacyjnych.

Funkcja Tangens Hiperboliczny (tanh)
Wzór:
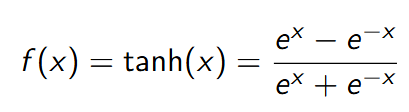
Zalety:
- Zakres wartości między -1 a 1, co jest przydatne w problemach
- klasyfikacji.
- Szeroki i różnorodny zakres dynamiki, co może prowadzić do szybszej
- zbieżności w uczeniu.
- Gładka i różniczkowalna, co ułatwia propagację wsteczną.
Wady:
- Problem z zanikającymi gradientami dla wartości dalekich od zera.
- Może być mniej efektywna w uczeniu głębokich sieci neuronowych niż
- ReLU.

Neuron sigmoidalny
Definicja:
Neuron sigmoidalny to rodzaj neuronu używanego w sztucznych sieciach neuronowych, który wykorzystuje funkcję aktywacji sigmoidalną do transformacji sygnałów wejściowych.
- Neuron sigmoidalny przyjmuje wejścia x1, x2, ..., xn, każde z nich jest ważone przez odpowiednie wagi w1, w2, ..., wn.
- Następnie suma ważona wejść jest przekształcana przez funkcję aktywacji sigmoidalną σ, aby uzyskać wyjście y .
Wzór dla wyjścia neuronu sigmoidalnego
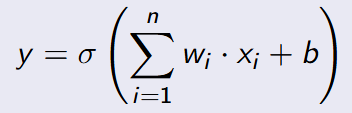
xi - wartość i-tego wejścia,
wi - waga przypisana do i-tego wejścia,
b - bias (przesunięcie),
σ - funkcja aktywacji sigmoidalna.
Reguła uczenia neuronu sigmoidalnego
Funkcja kosztu (błędu)
Do oceny jakości predykcji neuronu w stosunku do prawdziwych etykiet używamy funkcji kosztu. Przykładowe funkcje kosztu to błąd średniokwadratowy (MSE) lub entropia krzyżowa (cross-entropy).
- Błąd średniokwadratowy (MSE):

- Entropia krzyżowa:

Algorytm propagacji wstecznej
Algorytm:
- Oblicz błąd: error = ypred − ytrue
- Oblicz gradient: ∇J = X T · error
- Aktualizuj wagi: w = w − α · ∇

Przykład obliczeń oraz implementacje w Pythonie